I/O Management
Introduction
Section titled “Introduction”Let’s start this article with some schemas.
Schemas
Section titled “Schemas”Hardware architecture of a computing system
Section titled “Hardware architecture of a computing system”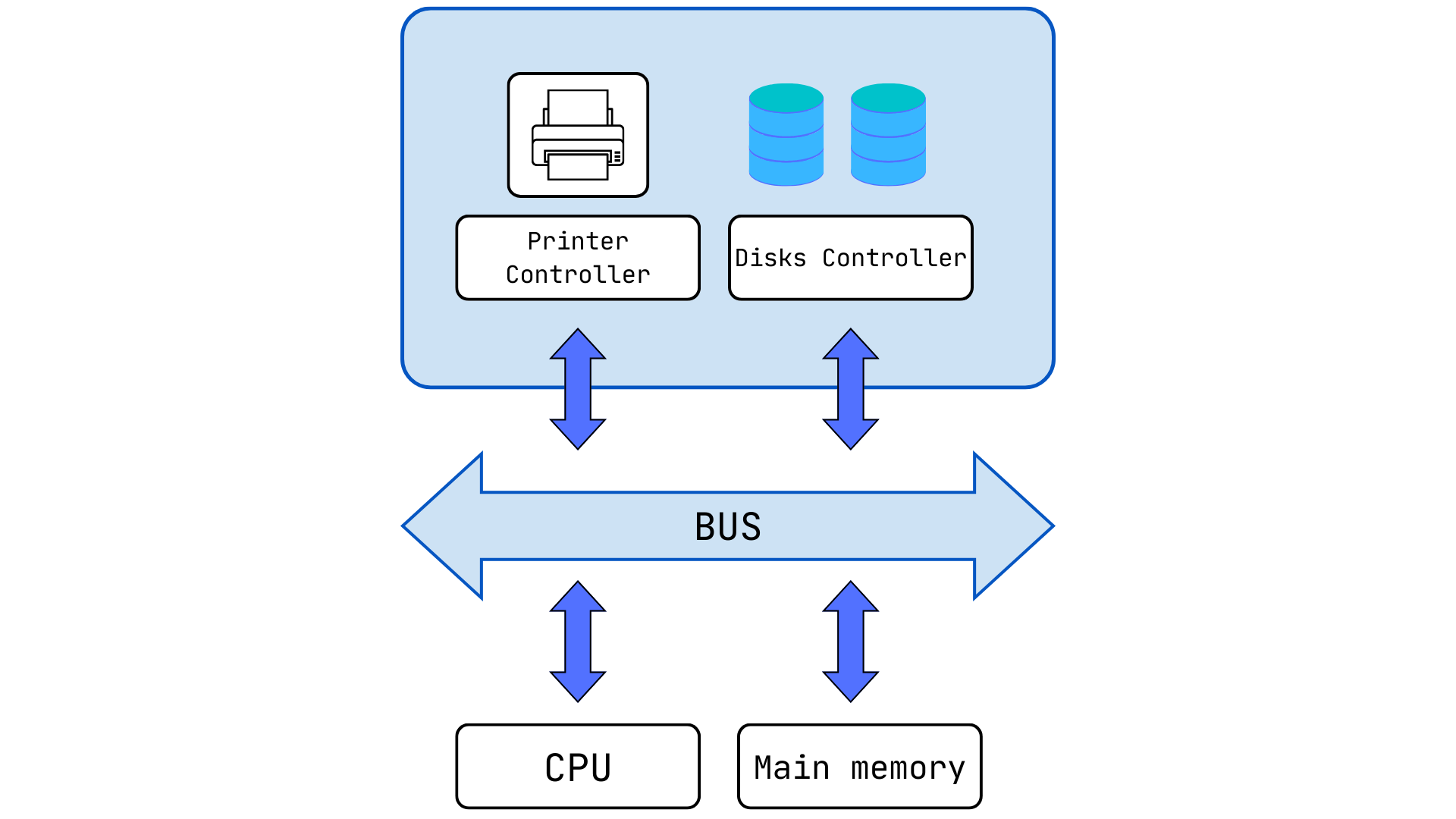
Logic management of I/O subsystem for devices
Section titled “Logic management of I/O subsystem for devices”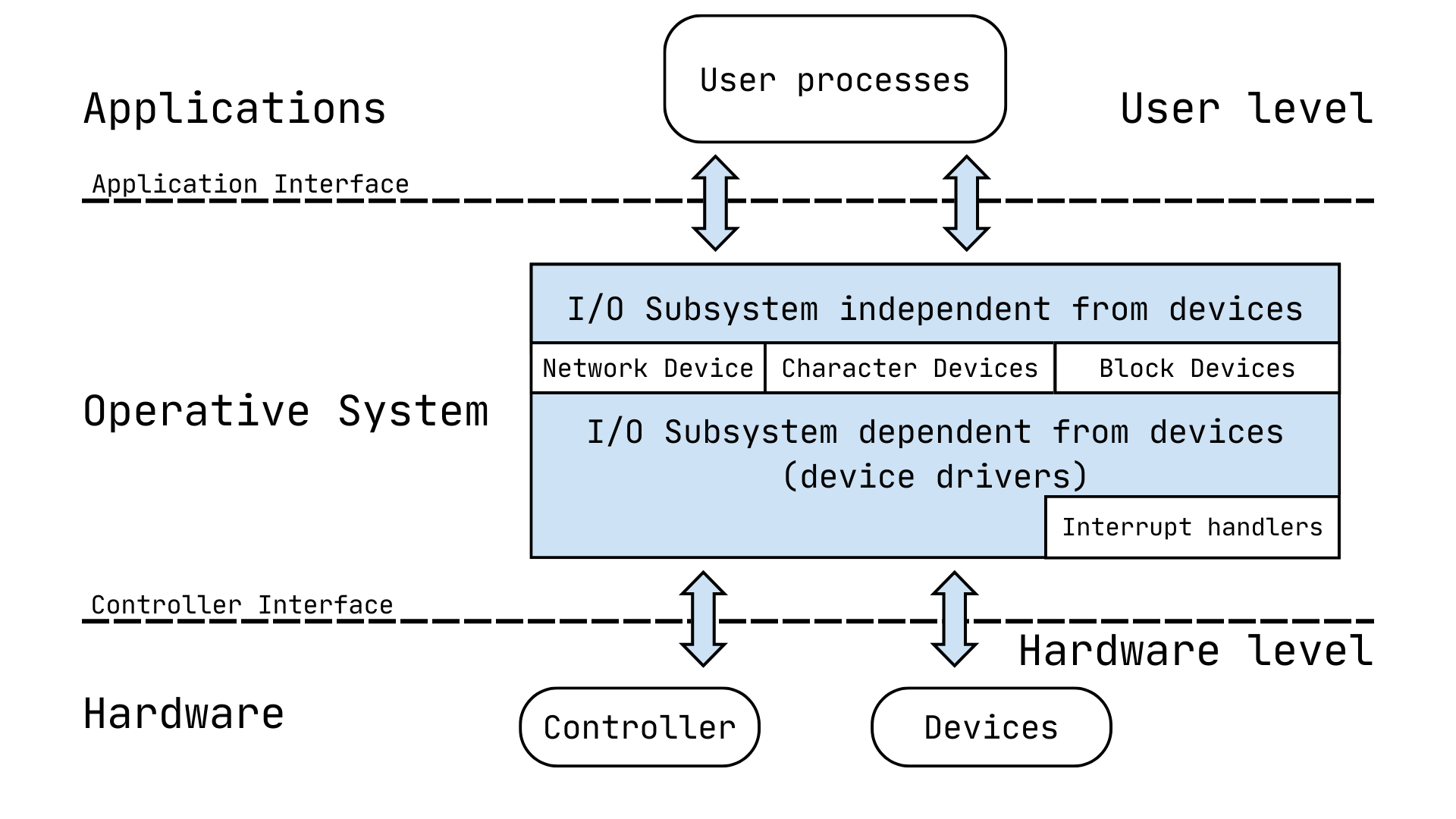
Device manager
Section titled “Device manager”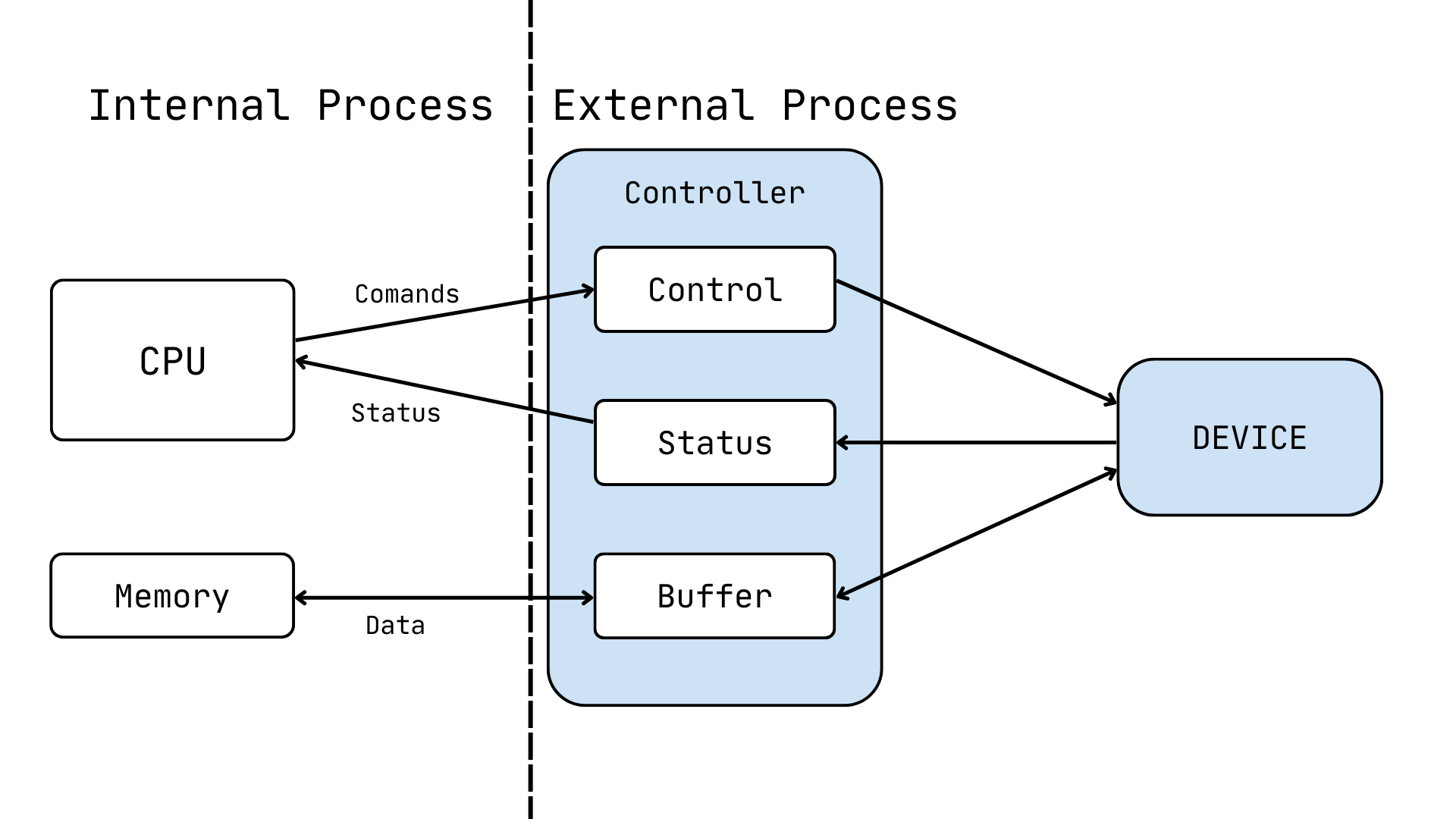
Terminology
Section titled “Terminology”Buffering
Section titled “Buffering”Buffering areas store data during transfer from devices and application processes’ memory areas. Buffering is useful to narrow down the differences between different speed of production and consuming of data, and to parallelize I/O accesses.
Exception management
Section titled “Exception management”During I/O operations may occur different anomalous events which can be masked and hidden from the users, or communicated and propagated to processes and users.
Naming
Section titled “Naming”Each device has a unique identifier.
Polling
Section titled “Polling”Device polling refers to a technique that lets the operating system periodically poll devices, instead of relying on the devices to generate interrupts when they need attention.
When done properly, polling gives more control to the operating system on when and how to handle devices, with a number of advantages in terms of system responsiveness and performance.
Spooling
Section titled “Spooling”Technique to manage shared resources. It avoids any kind of interference over resources and reduces waiting time for processes.
Interrupt-driven I/O
Section titled “Interrupt-driven I/O”In synchronous management, each process which wants to start an I/O operation is blocked waiting for the OS to terminate that request.
In asynchronous management, when the I/O operation ends, controller sends an hardware interrupt to the OS, which can then wake up the blocker process.
Interrupt-driven I/O management avoids polling and the related inefficiency lead by waiting times of processes.
Drivers are part of the operative system, they manage the devices.
A driver sends commands to controller and manage interruptions.
Hard Disk Management
Section titled “Hard Disk Management”Hard Disks provide mass memory, which is used by file system.
The sector is the minimum unit of allocation and transfer of memory. A sector is identified by number of disk side, track number and sector number inside the track.
Hard Disk performance is measured is term of average transfer time (TF), which is the sum of:
- TA: average access time (time to move the head)
- TT: average transfer data time (time to actually transfer data)
Moreover, the TA is the sum of:
- ST: time to longitudinally move the disk head on the required track (seek time)
- RL: time to rotate the disk in order to read the required sector (rotational time)
Disk performance is expressed in terms of round per minutes, usually between 5'400 and 15'000 rmp.
TT is in the order of microseconds.
ST and RL are in the order of milliseconds.
In a concurrent system, the file system must manage many requests from many processes. To reduce data access waiting time, scheduling policy must be established.
The most common policies are:
- FCFS: First Come First Served
- SSTF: Shortest Seek Time First
- SCAN: from 1st to last cylinder
RAID Disks
Section titled “RAID Disks”Redundant Array of Independent Disks systems are used to improve performance, reliability and fault tolerance.
It is based on different levels.
RAID 0 - Striping
Section titled “RAID 0 - Striping”A single logic volume is stored into different disks. The way data is allocated allows to parallelize I/O operations.
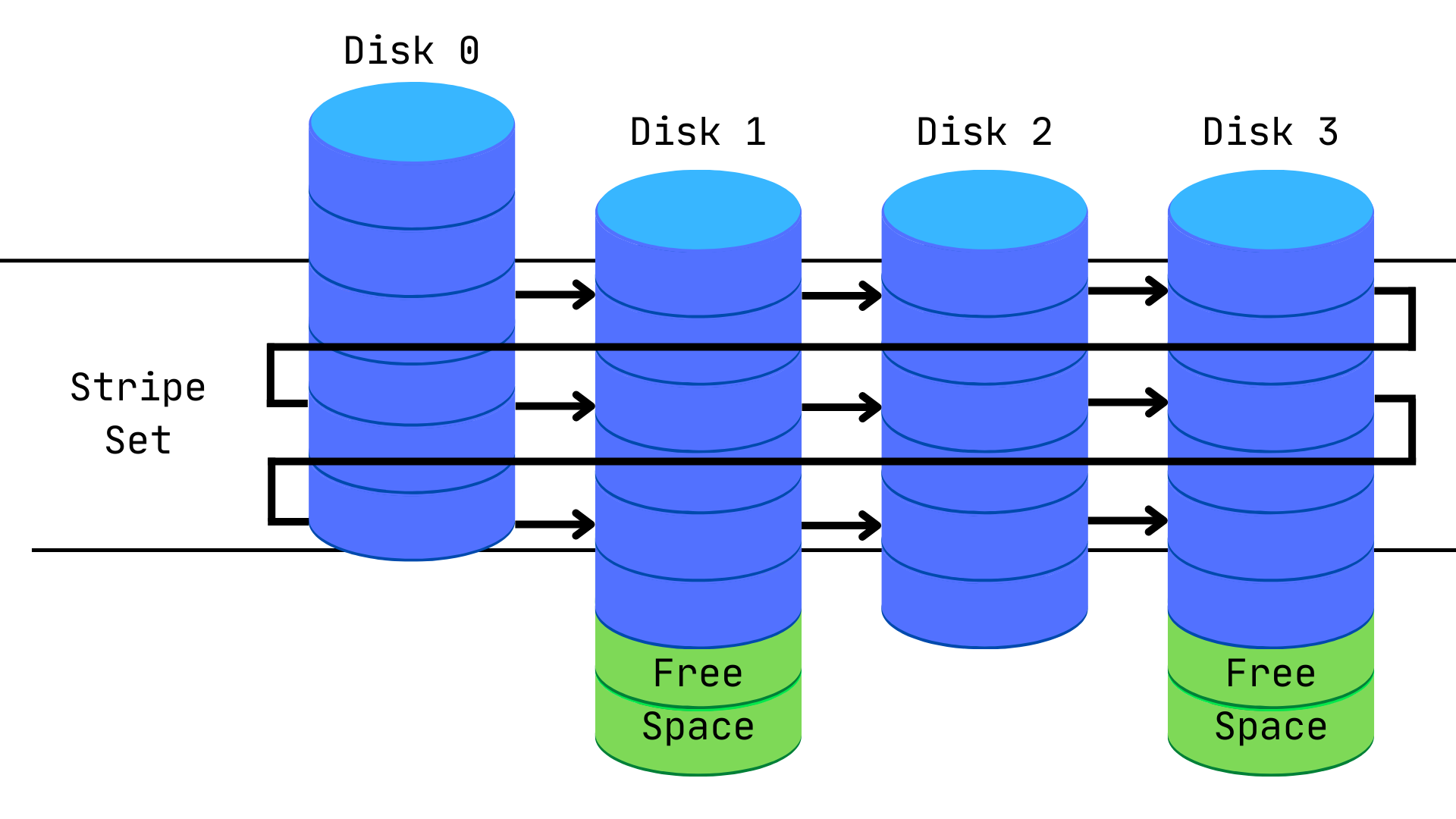
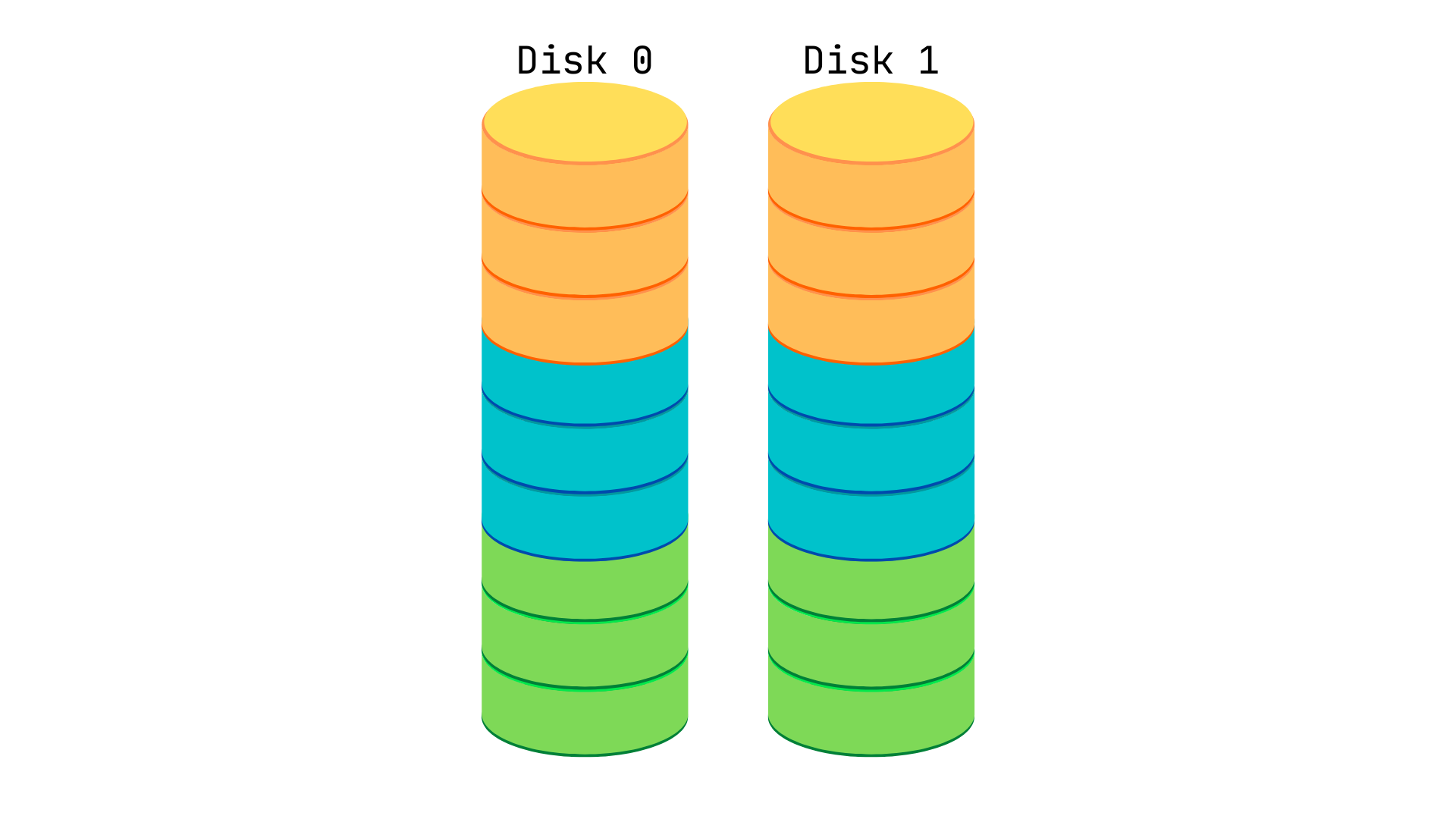
RAID 1: Mirroring
Section titled “RAID 1: Mirroring”The data is repeated on two disks. The first disk is mirrored on the second disk. Data is always written over both the disks. Reading can be parallelized.
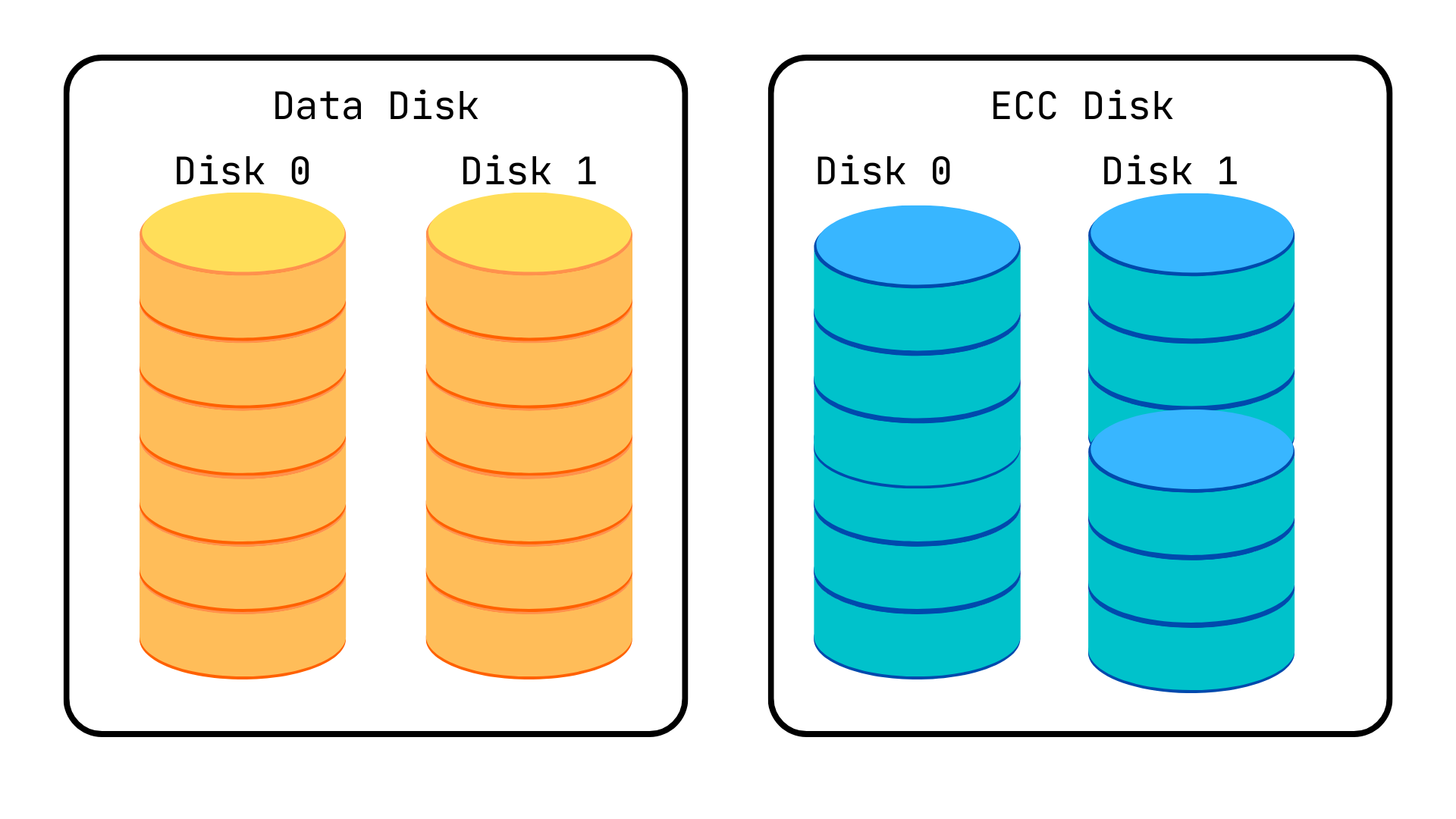
RAID 2: Striping with ECC
Section titled “RAID 2: Striping with ECC”A central controller synchronizes the disks by making them spin at the same angular orientation so that they all reach the index simultaneously. RAID 2 uses bit-level striping, and each sequential bit is placed on a different hard drive.
The error correcting code (ECC) used is the Hamming code parity, which is calculated across bits and stored separately in at least a single drive.
Other RAIDs types are:
- RAID 3: Striping with ECC stored as parity
- RAID 4: Striping with parity stored on a drive
- RAID 5: Striping with parity across more drives
File System Management
Section titled “File System Management”File systems allow memorizing data on secondary memory. From (user) application to secondary memory, there are the following levels of abstraction:
- Logical Structure: gives file and directory abstractions
- Access: access and protection policies
- Physical Structure: allocate file’s logic records on physical blocks of mass memory
- Virtual Device: gives the physic block abstraction to interpreter mass memory as a list of blocks
Logic Structure
Section titled “Logic Structure”Gives file and directory abstractions and the relative system calls to manage them.
A UNIX process interpreters the I/O word around it as a set of descriptors because of homogeneity between files and device.
Processes interact with I/O according to open-read-write-close paradigm: prologue and epilogue operations.
Access
Section titled “Access”A multi-user system must manage the access to files in order to guarantee the privacy for all users. Foreach file, the system could be defined different classes of users and different ways to access the file, which usually are:
- r: read
- w: write
- x: execute
Physical Structure
Section titled “Physical Structure”The most important allocation methods are: adjacent allocation, linked list allocation (with or without FAT table) and index allocation.
In Adjacent Allocation a file is allocated in an empty area major than the file dimension. This leads to fragmentation and needs periodical defragmentation routines of mass memory.
In Linked List Allocation there are no fragmentation issues. The sequential access is efficient.
Linked List Allocation with FAT table uses a FAT table as a data structure that describes blocks allocation map.
Lastly, Index Allocation in a non-adjacent allocation which does not causes fragmentation.
UNIX File System Management
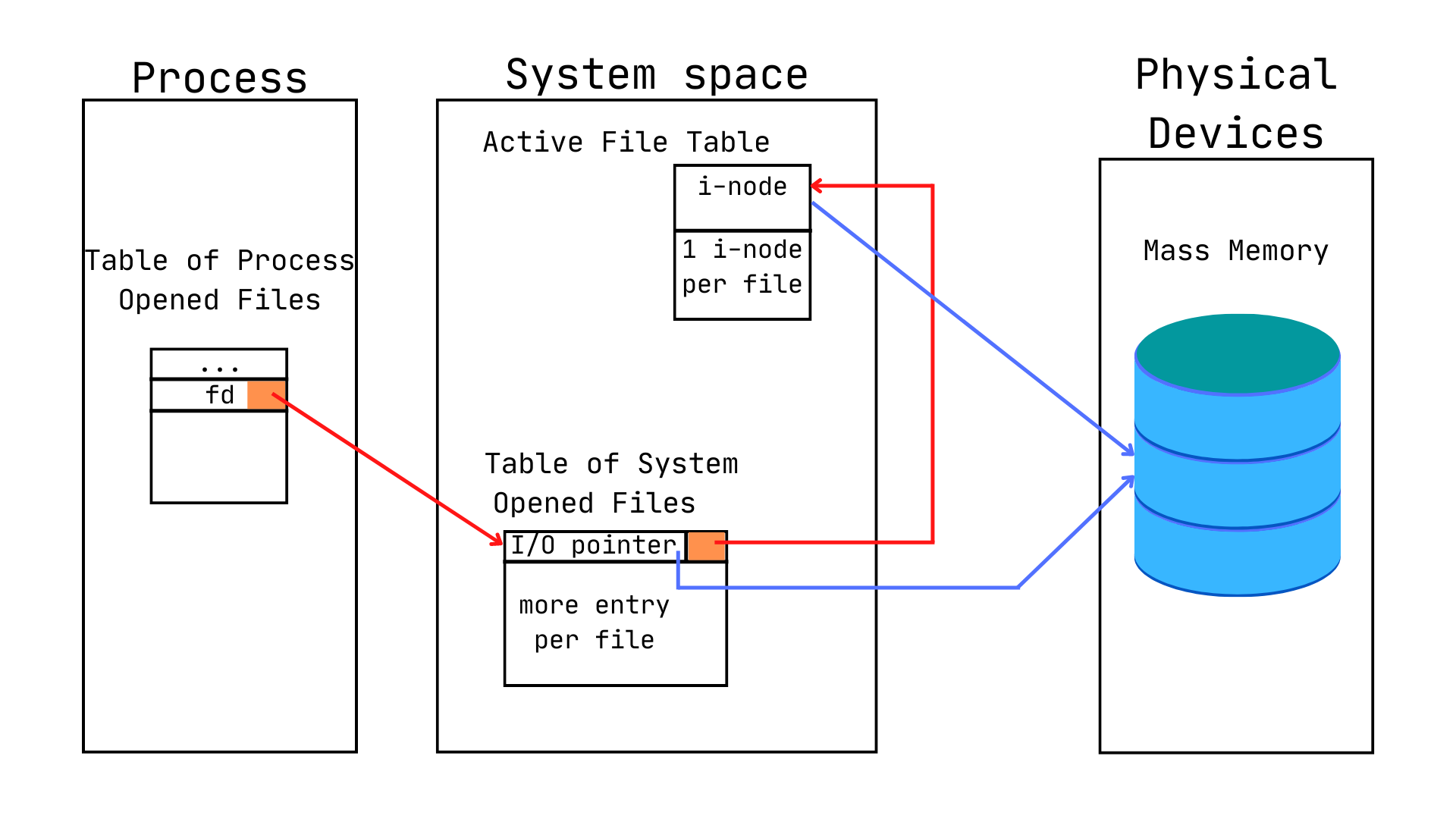
Section titled “UNIX File System Management”A file descriptor is a pointer to an i-node. It is a non-negative integer that identifies an opened file.
In UNIX’s System Programming, many variables contains fd in their names to refer the fact that they store file descriptors.
Each process has an I/O pointer that points to the current position of the file over which the process is currently operating. Each user as its own vision about opened files: if more users open the same file, each user process has its own I/O pointer.
UNIX Access
Section titled “UNIX Access”Take a look at File Protection slice of Introduction to UNIX article.
UNIX Physical Structure
Section titled “UNIX Physical Structure”Each file is represented by a descriptor (data structure) called i-node. i-node structure for devices is:
- ID number
- device class (blocks/chars) i-node structure for files and directories is:
- Owner:
UIDandGID - file type
- permissions
- bits:
SUID(Set owner User ID), SGID (Set owner Group ID) and sticky - links number
- file dimension
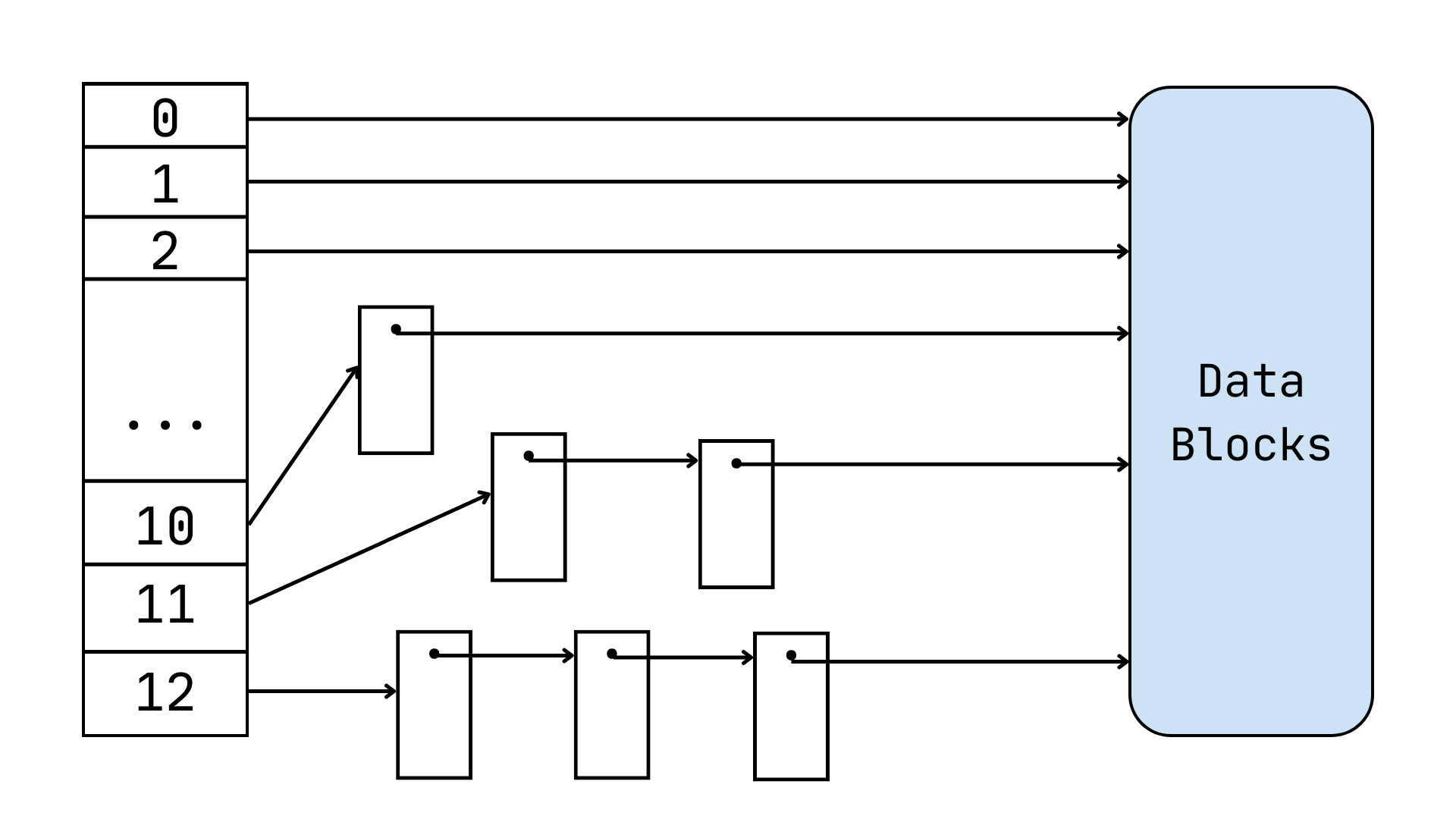
- allocation: addresses of thirteen blocks (index allocation)
Index allocation in Unix works in this way.
The first ten addresses (from 0 to 9) directly point to blocks on mass memory.
The 11th address has a level of indirectness: it points to a block that holds addresses to other 13 blocks.
The 12th address has two levels of indirectness and 13-th address has tree levels of indirectness.
The disk is subdivided into fixed-dimension blocks:
- boot-block
- superblock: describe the file system
- i-list: i-node list
- Data block
Share file between processes in UNIX
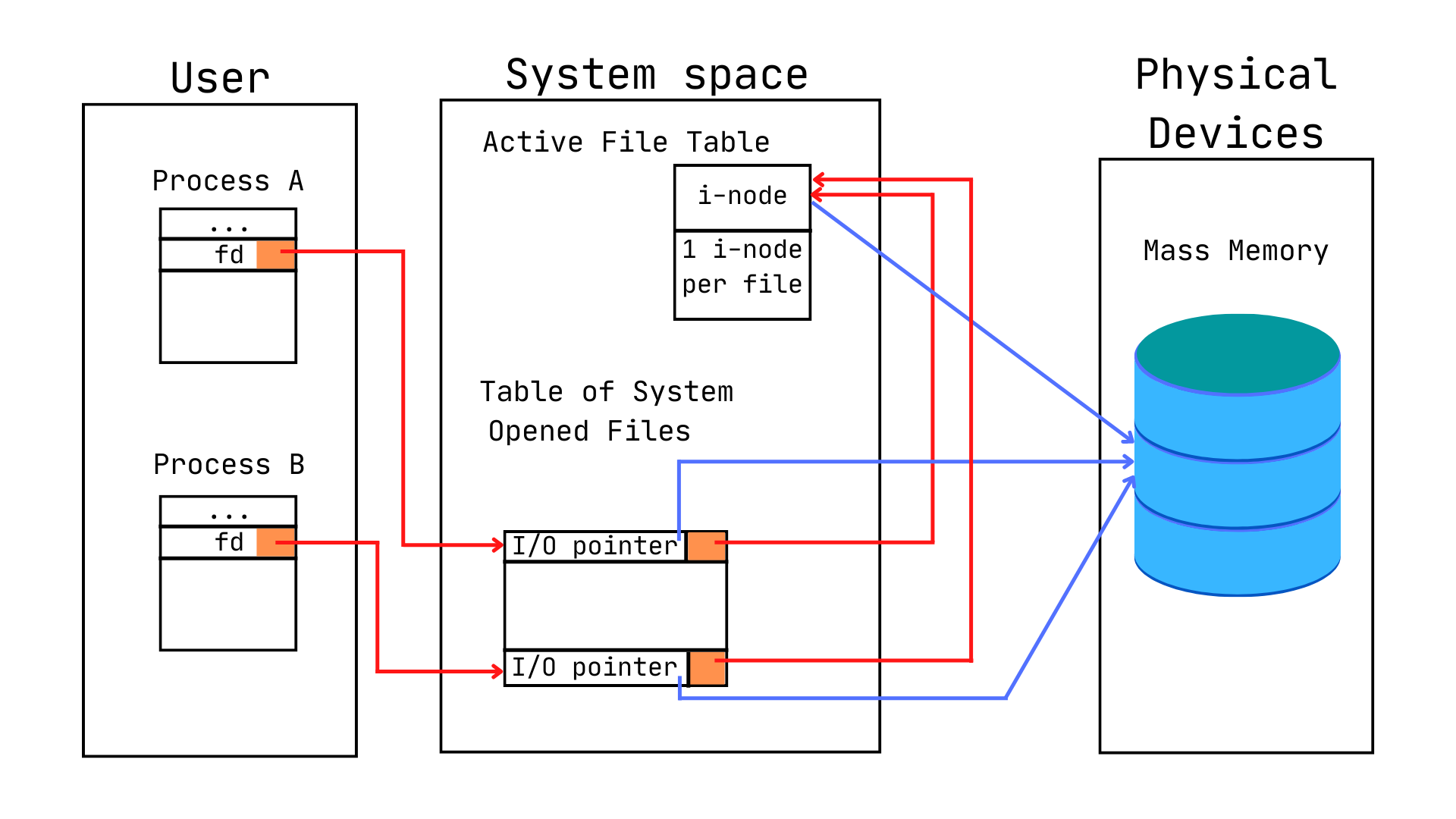
Section titled “Share file between processes in UNIX”Calling open() system call lead to the allocation of an element (a file descriptor) in the first available position of Table of Process Opened Files.
Then, a new record is added to Table of System Opened Files and a copy of its i-node is added to Active File Table (if the file has not been opened by another process).
If more processes open the same file, they:
- share a single entry in Active File Table
- have separate entries in Table of System Opened Files
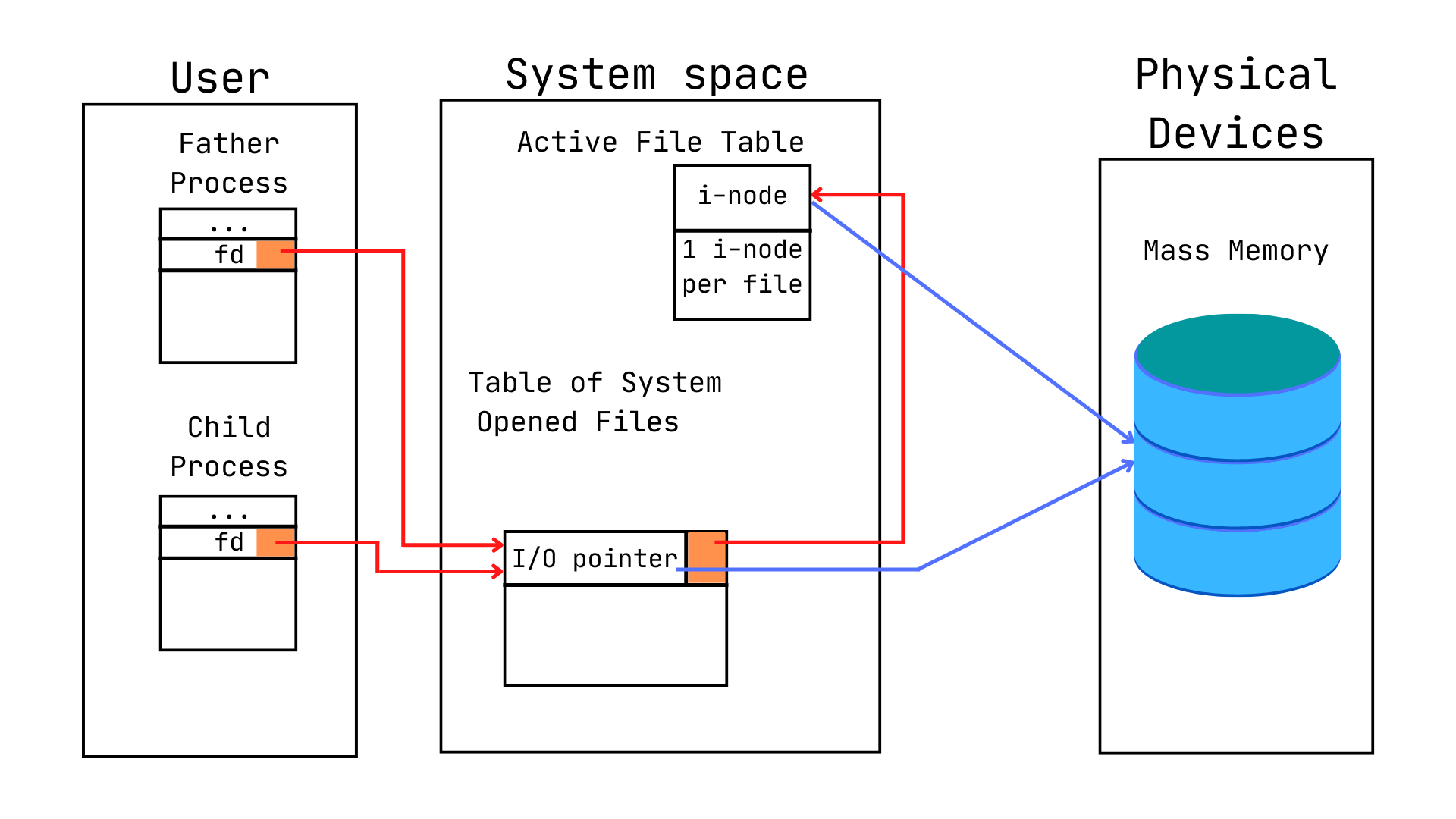
Let’s take a deeper look at the case of a process that opens a file before creating a child process.
Both father and child share the same entry in Table of Process Opened Files.
Due to this, they also share the same i-node inside Active File Table and the same I/O pointer.
Linux File System
Section titled “Linux File System”Let’s take, for example, any Linux-based Operative System. Its File System Hierarchy Standard is well-defined at pathname.com/fhs/.
As you can read in paragraph 3.2 Requirements of fhs-2.3.pd, the following directories (or symbolic links to directories) are required in / (root).
| Directory | Description |
|---|---|
bin | Essential command binaries |
boot | Static files of the boot loader |
dev | Device files |
etc | Host-specific system configuration |
lib | Essential shared libraries and kernel modules |
media | Mount point for removable media |
mnt | Mount point for mounting a filesystem temporarily |
opt | Add-on application software packages |
sbin | Essential system binaries |
srv | Data for services provided by this system |
tmp | Temporary files |
usr | Secondary hierarchy |
var | Variable data |
Protection & Security
Section titled “Protection & Security”Protection, on an operative system, is given by the guarantee that system resources are provided only to authorized subjects. Resources are meant as both logics and physics (CPU, memory, but also files, semaphores, pipes, …). Subjects are users, processes and procedures. Protection objective is to ensure that each active party in a system uses the resources only in the ways allowed by given predefined policies. The Reference Monitor is the operative system component that mediate between processors’ access requests and resources.
Least Privilege
Section titled “Least Privilege”Least Privilege principle tells that, in any instant of time, a process must access only to those strictly necessaries resources that allow the process to perform its right working.
Protection Domain
Section titled “Protection Domain”A protection domain defines a set of resources (objects, On) and the corresponding access rights (read, write, execute) allowed to subjects included in that domain.
A process (subject) works inside a protection domain that specifies the resources the process can use and with which access rights.
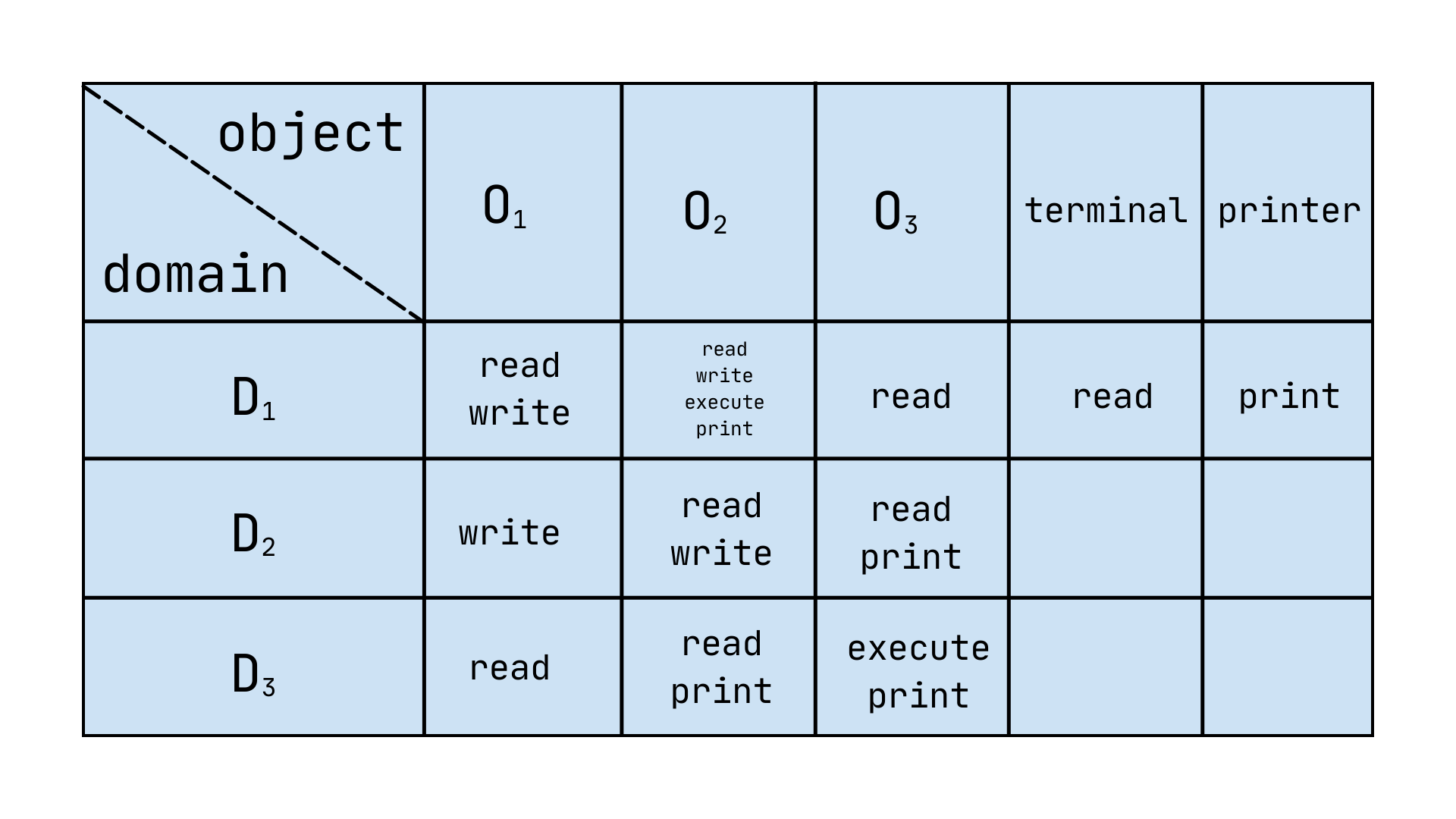
For example, protection domain D1 could consist of the following entities:
- <O1, { read, write } >
- <O2, {read, write, execute, print } >
- <O3, { read } >
Protection domain D2:
- <O1, { write } >
- <O2, { read, write } >
- <O3, { read, print } >
Protection domain D3:
- <O1, { read } >
- <O2, { read, print } >
- <O3, { execute, print } >
Access Matrix
Section titled “Access Matrix”Each matrix’s cell (indicated with access_matrix(i, j) C-style function) defines the set of access rights that a subject operating on a specific domain i can perform over the object j.
Starting from this table, it’s possible to archive an ordered set of triple:
<domain, object, set of access rights>When an operation M have to be executed on a domain Di over an object Oj, the operative system looks for triple <Di,Oj,Rk> with M ∈ Rk
If M exists, it can be executed, otherwise it’ll throw an exception.
Static VS Dynamic Domains
Section titled “Static VS Dynamic Domains”If the domain is static, the combination process-domain can’t change during the process’ life. If the domain is dynamic, a switch right allow a process to change its protection domain.
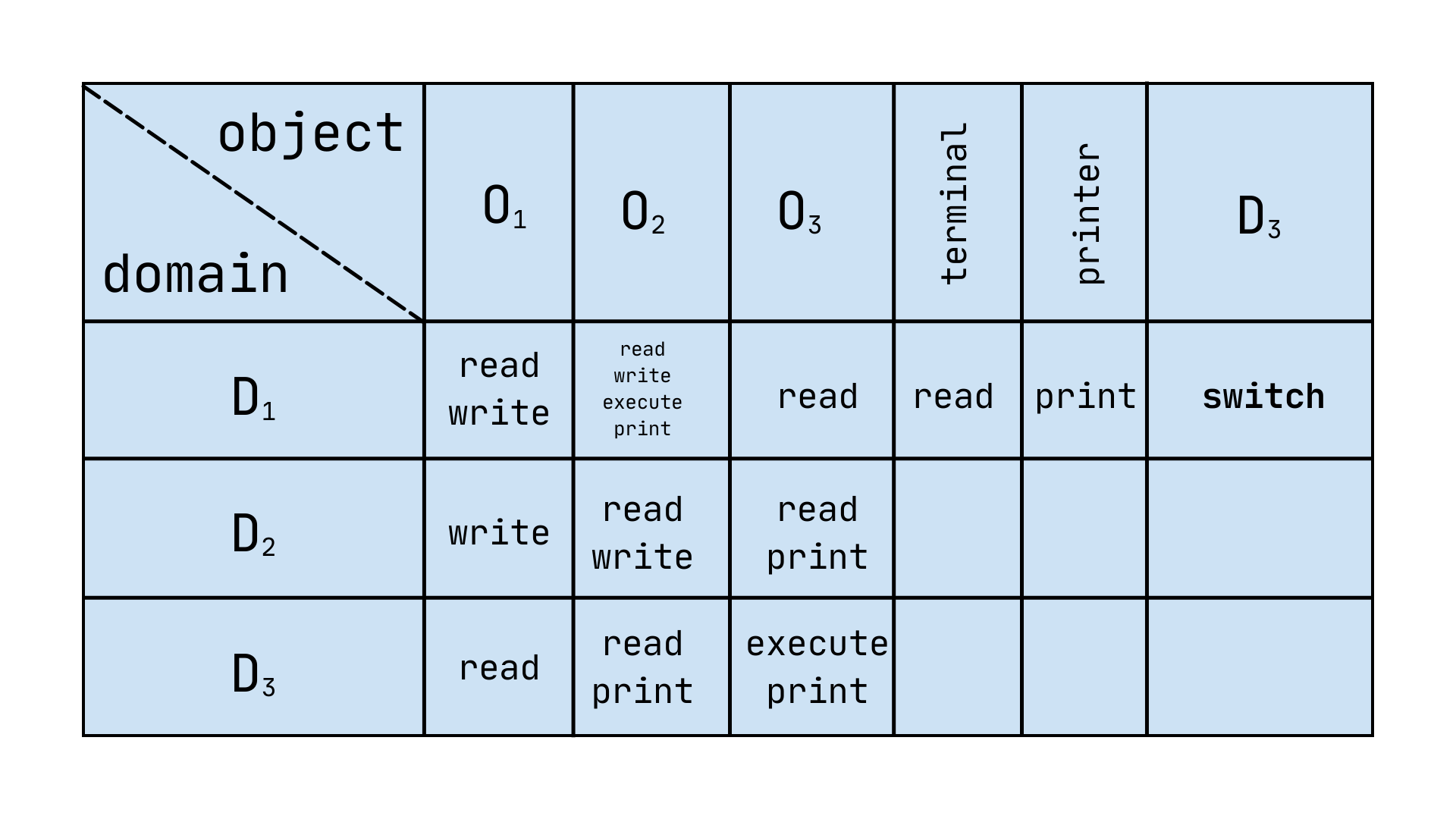
The problems related to Access Matrix come in play when the matrix starts to have a huge number of columns and rows, and many cells are left empty. To overcome those issues, the operative system can use tools like ACL (Access Control List) or Capability List.
Access Control List
Section titled “Access Control List”Foreach object, the ACL provides an order couple:
<domain, set of access rights>Those couples are valid only for domains with a non-empty set of access rights.
When an operation M have to be executed on a domain Di over an object Oj, the operative system looks inside the ACL for <Di,Rk> with M ∈ Rk
If M does not exists, M is searched in a sort of default list.
If M doesn’t even exists in this list, an exception is thrown.
To improve efficiency, the operative system can use the “default list” before using the ACL.
Capability List
Section titled “Capability List”Foreach domain, the Capability List provides the set of objects and the corresponding access rights. For example:
D1: <O1, rights>, <O2, rights>, ... and D2: <O3, rights>, <O7, rights>, ...
An object is usually identified by its physic name or by its capability. The ownership of a capability corresponds to the authorization of execute a certain operation. Capability List is protected and managed by the operative system: it cannot be manipulated by a user process.
Quotes
Section titled “Quotes”References: