Introduction
I really suggest you to take a brief look at a previous article I write, which acts as a sort of introduction: Network of Networks.
Web and HTTP
Until 90s, Internet was mainly used in the context of university research or, if you are less romantic (and you don’t believe this fairy tale), in the army’s communications. In the early 90s, Sir Tim Berners-Lee invented the World Wide Web.
The Web changed forever everyone’s life.
The Web acts on-demand: you can get anything you want, when you want it. It’s up to each of us to build the Web with what we would wish the most. In contrast to radio and television, where you can get the pieces of information only when the provider makes them available. Moreover, as I am doing writing this article, you can become a Web creator with extremely low costs.
HTTP Overview
Web’s application-level protocol is HTTP (HypterText Transfer Protocol). It is defined in RFC 1945, RFC 7230 and RFC 7540. I’ll talk about its very first versions (HTTP/0.9, HTTP/1.0 and HTTP/1.1), and I’ll get to HTTP/3 by passing through HTTP/2.
Please Note: a Request for Comments (RFC) is a publication in a series from the principal technical development and standards-setting bodies for the Internet.
HTTP defines both the messages’ structure and the modalities in which client and server exchanges messages.
The HTTP is a stateless protocol: the web server does not stores any information about the client’s state.
Terminology
A web page, also known as document, is made by objects. An object is a file: HTML file, JPEG image, CSS file, JavaScript file and so on). An object is uniquely addressable via a URL (Uniform Resource Locator). A web browser implements client-side HTTP. Within Internet, you can use the word client to refer to a web browser. Examples of web browsers are Google Chrome or Mozilla Firefox. A web server implement server-side HTTP. It houses web objects. Examples of web servers are Apache or nginx.
The most of the web pages are made made up by a base HTML file referencing many other objects.
HTTP uses TCP as transport protocol. The main advantage of a level-based architecture is that HTTP does not have to care about the messages’ transport, and TCP does not have to care about the messages’ format (it only transport them). Every component of the architecture minds his own duties.
HTTP does not concern the interaction of the web page by the user.
What is a URL
URLs usually reference web pages. Among other usages, URLs are also used for:
- file transfer via FTP (File Transfer Protocol),
- email using
mailtoURI (Uniform Resource Identifier), - database access JDBC (Java Database Connectivity)
A URL is made by:
- protocol
- server’s host name
- object path
For instance, take:
https://pietropoluzzi.it/hero-images/ubuntu-setup.pngThe protocol is https (adds a security layer to standard HTTP), the host name is pietropoluzzi.it, and the object path is /hero-images/ubuntu-setup.png. If you’re using a UNIX or UNIX-like machine, you can download a file from its URL using wget command open a shell terminal and type:
cd ~/Downloads
wget https://pietropoluzzi.it/hero-images/ubuntu-setup.pngYou can use your favorite file manager to open ubuntu-setup.png inside Downloads directory.
Persistent and Non-Persistent Connections
Within the context of a (web) client-server interaction, using a persistent connection implies that all HTTP requests are performed on the same TCP connection. A non-persistent connection implies that each pair of request-response is performed on a different TCP connection.
HTTP/1.0 uses non-persistent TCP connections: the browser opens 5 to 10 parallel TCP connections in order to lower down response time.
However, non-persistent TCP connections have performance limitations. For each requested object, the browser must establish and keep alive a new TCP connection. For each connection, both the client and the sever must allocate buffers and TCP variables.
HTTP/1.1 moves to persistent TCP connections. Over a single TCP connection, the client can request many web pages. Those requests can also be performed sequentially without waiting for responses of pending requests (pipelining concept).
HTTP Message Format
Let’s take, for instance, a GET request to pietropoluzzi.it/favicon.png object.
{kind=link}
The message is written in ASCII. Each line is followed by carriage return and line feed characters. The request must specify:
- method: GET, POST, PUT, PATCH, DELETE, HEAD, OPTIONS,
- URL: server’s host and object path
- HTTP version: 0.9, 1.0, 1.1, 2, 3
You can perform an HTTP request in many ways:
The request headers will be similar to:
GET /favicon.png HTTP/1.1
Host: pietropoluzzi.it
User-Agent: Mozilla/5.0
Accept: image/avif,image/webp,*/*
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Referer: https://pietropoluzzi.it/The User-Agent request header lets servers and network peers identify the application, operating system, vendor, and/or version of the requesting client.
The Host request header specifies the host (and port number) of the server to which the request is being sent.
The Connection header controls can have two different values:
keep-alive: the connection is persistent,close: the connection is not-persistent
The response headers will be similar to:
HTTP/2 200 OK
accept-ranges: bytes
age: 0
cache-control: public,max-age=0,must-revalidate
content-type: image/png
date: Mon, 25 Sep 2023 10:16:25 GMT
server: Netlify
content-length: 4010The first on is the status line, that specify:
- HTTP version used
- Code status:
- Informational responses (
100–199) - Successful responses (
200–299) - Redirection messages (
300–399) - Client error responses (
400–499) - Server error responses (
500–599)
- Informational responses (
It’s important to note that the date contains the date and time at which the message was created. It becomes important when talking about proxy servers and cache.
Cookies
Since HTTP servers are stateless, they have to develop a way to identify different users and handle, for instance, authentication or a virtual chart (for e-commerce web applications). HTTP uses cookies to allow the persistence of a state.
Cookies can be used to create a user-session level above HTTP.
Cookies caused many legal disputes since they can be used to violate user’s privacy. For this reason, I prefer not to go into further details and rely on a follow-up article.
Web Caching
A web cache, also known as proxy server, is a network entity that reply to HTTP requests in place of the actual server. It stores a copy of the recently asked objects (HTML files, JS scripts, …).
A proxy is both client and server at the same time. A proxy is configured by an ISP (Internet Service Provider). It became crucial with the rise of CDN (Content Distribution Network) companies like Netflix or Prime Video. A CDN have many proxy server around the globe.
Web caching has been developed to reduce:
- response time to HTTP clients
- network traffic over the Internet access
Conditional GET
An object within the proxy server could have been expired. HTTP provides conditional GET method (RFC 7232) alongside the standard GET method. The proxy uses conditional GET to check if an object is up to date. The conditional GET is like a standard GET, but adds the If-modified-since header line. If the requested object has not been modified, the server will reply with a 304 status (Not Modified) and an empty body message.
HTTP/2
HTTP/2 aims to reduce perceived latency by enabling both request and response multiplexing over a single TCP connection. Sending all the page’s objects over a single TCP connection causes HOL block issue. Where HOL stands for Head Of Line.
HTTP/2 aims to cut to the bone the parallel TCP connections used to deliver a single web page. As a result, the number of sockets decrees, and allows TCP congestion control to work properly.
HTTP/2 Framing
HTTP/2 solves HOL block issue by subdividing the messages in smaller frames and alternate request and response messages over the same TCP connection.
HTTP/3
HTTP/3 version is currently under development. It is based on QUIC (RFC 9000), a UDP-based protocol. Note that QUIC is not an acronym. I’ll talk about it on a follow up article.
DNS: Internet’s directory service
Note that directory is not intended in the meaning of folder, like it does in Operative System-related articles. Directory can be seen as a synonyms of manual or phonebook, which is actually a telephone directory.
Every Internet host is identified by both its hostname and its IP address.
Let’s take for instance Google search engine. It is available at the hostname www.google.com. Using nslookup command, you can get (one of the many) google’s IP address: 216.58.204.132. If you past this address to the web browser, you’ll get the Google search engine web page. Let’s try to click this link: 216.58.204.132. That’s crazy!
I’ll make more examples with nslookup down below.
DNS’ Services
Users use hostnames, while surfing to the Internet: they’re are more human-readable. Routers and switches use IP addresses cause of their fixed length. Internet must have a way to translate a hostname to the corresponding IP address and vice versa: it’s where DNS comes into play. DNS (Domain Name System) is UPD based, and uses port 53 by default.
DNS is made by:
- distributed database hierarchically organized
- application-level protocol that allow hosts to query the database
DNS servers are usually UNIX-based machines that runs BIND (Berkeley Internet Name Domain) software.
DNS is transparent to the actual user: it is queried by other application-level protocols like HTTP and SMTP. The steps performed when connecting to a server are:
- the user runs client-side DNS application (DNS client)
- the browser extract the hostname from URL and gives it to the DNS client
- the DNS client sends a query to a DNS server providing the hostname
- after a given period of time, the DNS client receives a response with the corresponding IP address
- the web browser can start a TCP connection to the HTTP server listening on port
80opened on that IP address
DNS’s IP address resolution adds more delay to Internet applications. DNS also provide the folloeing services:
- Host Aliasing
- Mail server aliasing
- Load Distribution
Host & Mail server Aliasing
An host has a canonical name and one or more aliases (synonymous). DNS is queried when an Internet entity wants to know the canonical name of a server starting from an alias. This kind of aliasing is also performed over mail providers. Mail server aliasing enables a company (like Ducati) to have the same alias for both its web server and its mail server. For example, you can browse www.ducati.com website and write e-mails that to the domain @ducati.com (like info@ducati.com or ceo@ducati.com).
Load Distribution
When dealing with replicated servers, like www.google.com, a single canonical hostname corresponds to a set of IP addresses. When a client queries the DNS with a name associated to a set of addresses, the DNS server reply with the whole list of the IP addresses changing the order of the elements in the list. The client will almost certainly perform its HTTP request to the first element of that list. This ensure replicated server usage rotation.
DNS working overview
DNS is organized into a huge number of hierarchically distributed servers. There are approximately three classes of DNS servers:
- root Nearly one thousand world wide, copies of 13 “original” root servers managed by 12 different organizations coordinated by IANA.
- TLD (Top Level Domain) Manage first level domains (.com, .org, .gov, …)
- authoritative Every organization provided with Internet-accessible hosts must provide publicly accessible DNS records
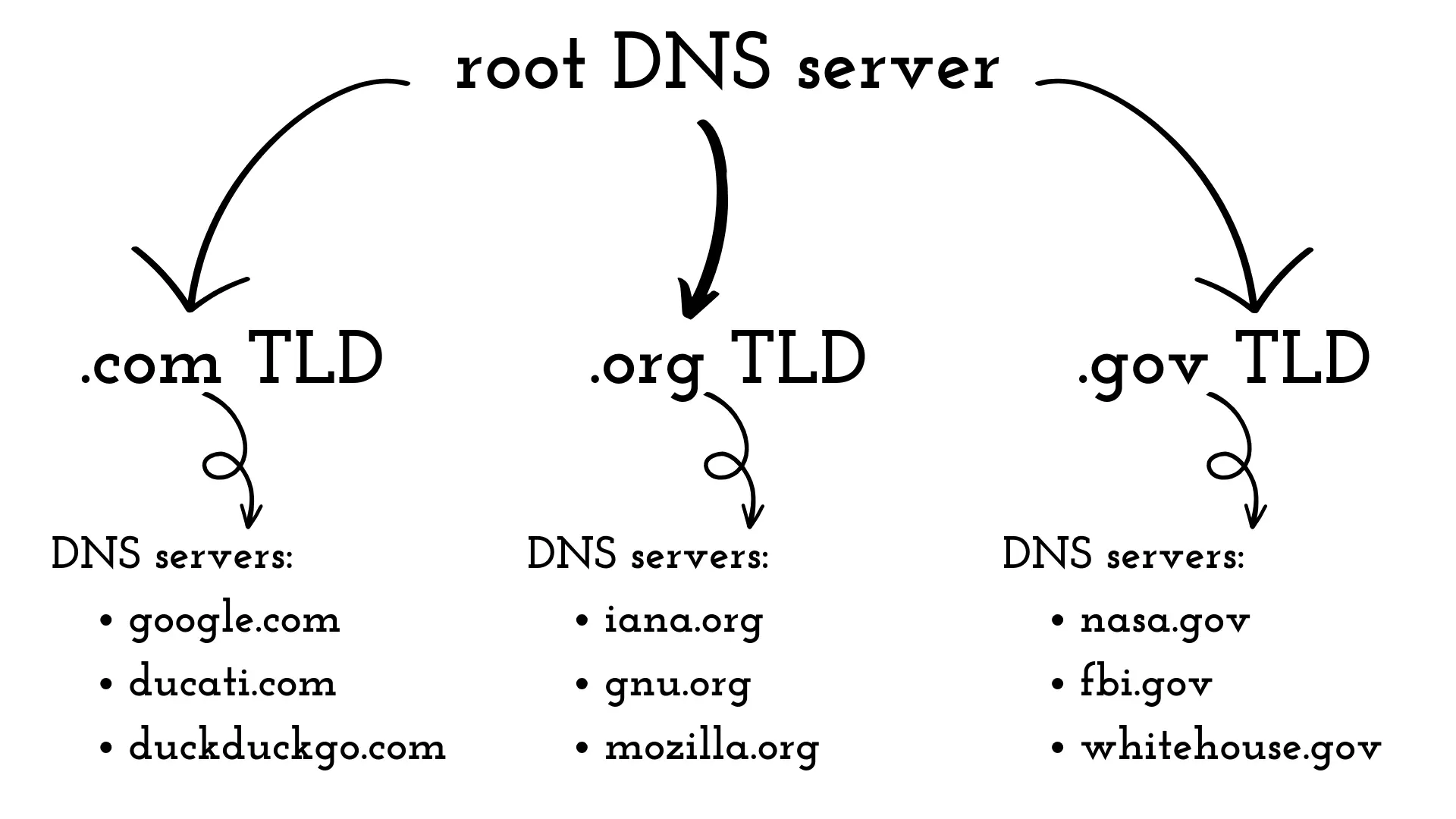
Alongside the hierarchy, there is another kind of server: the LDNS (Local DNS). Each ISP has its own LDNS called default name server. When an host connects to an ISP, the provider will reply with an IP address from one of the nearby LDNSs.
P2P File Distribution
This section is focused on the differences between P2P and client-server architectures in a real case scenario: the distribution of a large file over the Internet (like an OS update or a video). In this section, the terms peer and client will be used as synonyms.
P2P scalability
Let’s start with the client-server architecture. Given the following variables:
- F: dimension in bits of the file to distribute,
- N: number of peers that request a copy of the file
- us: upload bandwidth of the server access point,
- ui: upload bandwidth of the -th peer,
- di: download bandwidth of the -th peer,
- the peers’ lowest download bandwidth
Note that upload and download bandwidth is measured in bps (bit per seconds)
Moreover, to simplify the formulas, let’s suppose that:
- Internet’s core have endless bandwidth: bottlenecks are in the access networks
- both the server and the clients are not taking part of any other network application
It’s possible to state that:
- the server transmits bits overall,
- distribution time must be at least ,
- minimum time of distribution is at least .
The effective time of distribution in a client-server architecture is then:
For (big enough):
On the other hand, on the P2P architecture, the peers can use their upload bandwidth to re-distribute file pieces (chunks) to other peers. Given all the variables defined above, and given as the whole upload bandwidth of the system (server and peers):
At the beginning of the exchange, only the server have the file. It implies that the minimum distribution time is . The peer with the lowest bandwidth gets the whole file in time. Given , the minimum time of distribution is at least .
The effective time of distribution in a P2P architecture is then:
To summarize, in the client-server architecture the distribution time grows linearly. While in the P2P architecture, the distribution time scales it self based on the peers number.

Video Streaming
A video is a sequence of images at a given rate, usually measured in fps (frame per seconds). In terms of networks, the most important feature of a video is its speed at which bits need to be sent over the network: the bit rate.
HTTP and DASH Streaming
In HTTP streaming, the video is stored on the server, and accessible using an URL. The client request the video using an HTTP GET call. Bytes are stored in a client-application buffer. When the buffer reach a given threshold, the video starts to reproduce. The frames are taken from the buffer, decompressed and shown to the user. Meanwhile, the client continues to ask the server for the video’s frames through a TCP connection.
In place of HTTP, CND companies has started to use DASH (Dynamic Adaptive Streaming Over HTTP). DASH allows clients with different download bandwidth to perform different video streaming by making available different “versions” of the same video at different bit rates. DASH also allows to adapt the choose of the video “version” based on the available bandwidth, in case it changes during the streaming.
Socket Programming
Let’s take a simple example to show how sockets works with both UDP and TCP protocols.
The client asks the user to insert a string, and sends it to the server through the socket. The server modify the given string (like making it uppercase or applying a Caesar encryption) and sends it back to the client which visualize the modified message and close the socket connection.
Let’s make a few clarifications for the Python scripts. I do not like to import the whole socket library with:
from socket import *
# ...
mySocket = socket(AF_INET, SOCK_DGRAM)If you import many libraries in the above way, you can confuse where methods came from. Instead, I prefer:
import sockets
# ...
mySocket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)It is always discouraged to use hard-coded variables: it limits the re-usability of the code. The examples below are an oversimplification: you should have used sys.argv to pass parameters to your Python scripts.
The scripts below are extensively commented!
UDP Socket Programming

UDP Client
Let’s create the UDP_client.py script.
#!/usr/bin/env python3
import socket
# >>> START: hard-coded variables <<<
# IP address of the server
# use 'localhost' if it is on the same machine
serverName = 'localhost'
# server port number
serverPort = 10123
# socket buffer size
BUFF_SIZE = 2048
# >>> END: hard-coded variables <<<
# create client-side socket
# AF_INET parameter tells the underlying network is IPv4-only
# SOCK_DGRAM parameter specify UDP as transport protocol
clientSocket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
print(">>> UDP client ready")
# take the input string from the user
msg = input('>>> statement input: ')
# encode the message from string to bytes
# send the encoded message to the server through the socket
clientSocket.sendto(msg.encode(), (serverName, serverPort))
# client waits for a response from the server
# the buffer is specified by BUFF_SIZE variable
rxMsg, serverAddress = clientSocket.recvfrom(BUFF_SIZE)
print(">>> server address: {}:{}".format(serverAddress[0], serverAddress[1]) )
print(">>> received message: ", rxMsg.decode())
# close the socket and exit the script
clientSocket.close()
print(">>> Client socket closed")UDP Server
Let’s also create the UDP_server.py script.
#!/usr/bin/env python3
import socket
# >>> START: hard-coded variables <<<
# server port number
serverPort = 10123
# socket buffer size
BUFF_SIZE = 2048
# >>> END: hard-coded variables <<<
# create client-side socket
# AF_INET parameter tells the underlying network is IPv4-only
# SOCK_DGRAM parameter specify UDP as transport protocol
serverSocket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# assign 'serverPort' value to server-side socket port
serverSocket.bind(('', serverPort))
print(">>> UDP server ready")
# run forever
while True:
# wait for packets to come
# store both the message and the arriving address (client)
msg, clientAddress = serverSocket.recvfrom(BUFF_SIZE)
print(">>> client address: {}:{} ".format(clientAddress[0], clientAddress[1]))
# modify the message received from the client
modifiedMsg = msg.decode().upper()
# some debugging output
print(">>> message received from client: ", msg.decode())
print(">>> message ready to be sent back: ", modifiedMsg)
# send the message back
serverSocket.sendto(modifiedMsg.encode(), clientAddress)Now let’s open a terminal windows and allow script execution:
chmod +x UDP_client.py UDP_server.pyThen open two different shells, on the first one run the server:
./UDP_server.pyOnce the server is up and running, open another window to run the client:
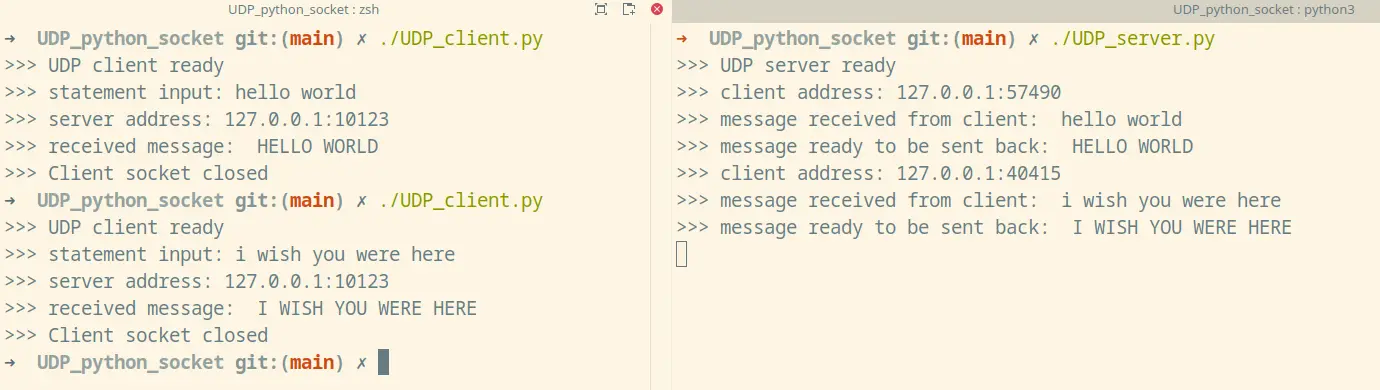
./UDP_client.pyThe screenshot below shows the execution of a couple of client requests:
Please Note: to stop the server execution use Ctrl+C.
TCP Socket Programming

The TCP’s handshake must be performed over a reversed socket, which is different from the socket used to exchange messages.
TCP Client
Let’s create the TCP_client.py script.
#!/usr/bin/env python3
import socket
# >>> START: hard-coded variables <<<
# IP address of the server
# use 'localhost' if it is on the same machine
serverName = 'localhost'
# server port number
serverPort = 10123
# socket buffer size
BUFF_SIZE = 2048
# >>> END: hard-coded variables <<<
# create client-side socket
# AF_INET parameter tells the underlying network is IPv4-only
# SOCK_STREAM parameter specify TCP as transport protocol
clientSocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# start the connection in order to
# perform the handshake procedure
clientSocket.connect((serverName, serverPort))
print(">>> TCP client ready")
# take the input string from the user
msg = input('>>> statement input: ')
# send message
clientSocket.send(msg.encode())
# client waits for a response from the server
rxMsg = clientSocket.recv(BUFF_SIZE)
print(">>> received message: ", rxMsg.decode())
# close the socket and exit the script
clientSocket.close()
print(">>> Client socket closed")TCP Server
Let’s create the TCP_server.py script.
#!/usr/bin/env python3
import socket
# >>> START: hard-coded variables <<<
# IP address of the server
# use 'localhost' if it is on the same machine
serverName = 'localhost'
# server port number
serverPort = 10123
# socket buffer size
BUFF_SIZE = 2048
# maximum number of connected clients
MAX_CLIENT_NUM = 10
# >>> END: hard-coded variables <<<
# create server-side socket
# AF_INET parameter tells the underlying network is IPv4-only
# OCK_STREAM parameter specify TCP as transport protocol
serverSocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# serverSocket is the socket where to perform the handshake
serverSocket.bind(('', serverPort))
# allow listening on TCP connection
# for at most MAX_CLIENT_NUM clients
serverSocket.listen(MAX_CLIENT_NUM)
print(">>> TCP server ready")
while True:
# block the server execution until
# client starts connection procedure
# connectionSocket is a new socket for the connected client
connectionSocket, addr = serverSocket.accept()
# receive bytes from the TCP connection
# and decode them into a string
msg = connectionSocket.recv(BUFF_SIZE).decode()
print(">>> connection socket: {}, address: {} ".format(connectionSocket, addr))
# modify the message received from the client
modifiedMsg = msg.upper()
# some debugging output
print(">>> message received from client: ", msg)
print(">>> message ready to be sent back: ", modifiedMsg)
# send the message back
connectionSocket.send(modifiedMsg.encode())
# close the connection and wait back
# for clients to connect
connectionSocket.close()Now let’s open a terminal windows and allow script execution:
chmod +x TCP_client.py TCP_server.pyThen open two different shells, on the first one run the server:
./TCP_server.pyOnce the server is up and running, open another window to run the client:
./TCP_client.pyThe screen-shot below shows the execution of a couple of client requests:

Sockets Theory
Within socket.socket method, the socket types are:
| Type | Protocol used |
|---|---|
SOCK_STREAM | TCP: Transmission Control Protocol |
SOCK_SEQPACKET | SCTP: Stream Control Transmission Protocol |
SOCK_DGRAM | UDP: User Datagram Protocol |
SOCK_RAW | raw access to IP (Internet Protocol) |
SOCK_DCCP | DCCP: Datagram Congestion Control Protocol |
Put simply, DCCP is UDP plus congestion control.
As I told you within the code, AF_INET parameter tells the underlying network is IPv4-only. Nowadays, Internet uses IPv6 for more than 40% of the global traffic. The parameter AF_INET6 allows Internet IPv6-enabled communications between sockets. It ensure retro-compatibility with IPv4.
That parameter can also be set to AF_UNIX: communication between UNIX processes. The socket address has the same format of a file name.